
keonwookim.github.com
Your stylish, minimalist theme!
톰캣을 이용하다보면 하나의 서버에서 멀티 인스턴스를 실행시킬 일이 생기게 된다. 본인의 경우에는, 개발을 위한 테스트 환경때문에 멀티 인스턴스를 띄울일이 있었는데 톰캣에서의 멀티 인스턴스를 생성하는 방법에 대해 알아보도록 하자. 구동에 필요한 톰캣 및 JDK 설치는 완료되었다고 가정하고 진행하도록 하겠다.
인스턴스들이 저장될 인스턴스들을 관리할 디렉토리를 생성한다. 적당한 위치에 디렉토리를 생성한다. 설치한 톰캣 디렉토리나 사용자 홈디렉토리 등을 이용해서 적당한 이름(instances, deploy or…)의 디렉토리를 생성한다. 인스턴스 디렉토리안에 실제 띄울 인스턴스 디렉토리를 생성한다. 본인은 api(~/instances/api)라는 이름으로 생성하였다.
인스턴스 디렉토리(~/instances/api)에 conf/server.xml 파일을 수정한다. conf/server.xml파일의 Connector port를 사용할 포트로 변경해준다. 또한 shutdown port를 찾아서 포트넘버를 적절히 바꿔준다. shutdown 포트는 해당 인스턴스의 shutdown명령을 받을 포트이다.
$CATALINA_HOME/bin/startup.sh, $CATALINA_HOME/bin/shutdown.sh 파일을 수정한다. #bin/sh 아래 다음과 같이 입력한다.
INSTANCE_NAME=$1
export JAVA_HOME={자바 설치 위치}
export CATALINA_HOME={tomcat 설치 위치}
export CATALINA_BASE=$CATALINA_HOME/instances/$INSTANCE_NAME
쉘에서 다음과같이 입력한다.
$CATALINA_HOME/bin/startup.sh {실행할 인스턴스 이름}
위의 명령어를 실행하면 톰캣 인스턴스가 실행되며. logs디렉토리의 catalina.out 파일을 tail -f catalina.out 출력시켜서 잘 실행이 되는지 로그를 확인한다.
실행이 필요한 인스턴스들이 더 있다면 인스턴스 디렉토리(~/instance/) 밑에 생성해주고 위의 내용을 수행하면된다.
#Reference
이전 포스트를 잘 따라했다면, Idea 상에서 무리없이 실행이 될 것이다. 한 번 실행을 해보도록 하자. 메뉴의 Run > Edit Configurations..를 선택한 후 좌측 상단의 +버튼을 이용해 SBT Task를 선택한다. 선택하면 우측에 설정하는 부분이 나오는데 이름을 적당히 적어주고, Tasks에 run을 입력하면 된다. 이후 Alt+Shift+F10을 눌러서 실행해주면 된다.
#Play Framework in IDEA Community Edition
#Play Framework
나는 자바스크립트 무식자다. 해본거라곤 학부 때 조금? 하여 jQuery역시 잘 모른다. (자랑은 아니지만…) 메신저 관리페이지 관련하여 Front-end쪽을 수정 및 추가해야할 일이 생겼다. 무식자이기 때문에 약간의 두려움을 가지고 코드를 들여다 보았다. 그래도 이전에 한번 손댄적이 있었기에 낯설지 않았다. 이번에도 데드라인이 코앞이었기 때문에 마음도 급하고, 뭐를 먼저해야할지 좀 정신없이 시작한 것 같다. 어쨌거나 엄청난 삽질을 했었는데, 삽질에 대해서 이야기해보독 하겠다..
사건은 jQuery template에서 시작한다. 우선 jQuery template에 대해서 알아보도록 하자. 이름에서도 느껴지듯이 template이다. 뭔가 기본틀을 만들어놓고 마구 찍어낼거같은 느낌이 든다. 그렇다. jQuery template이용해서 Javascript 데이터를 HTML로 작성된 템플릿에 바인딩 시켜서 HTML DOM내에 렌더링 할수 있다. 그럼 이쯤에서 예제를 보자.
<div id="access_log_list" class="access_log_list fill">
<table id="access_log_table" class="table">
<thead>
<tr>
<th>접근시간</th>
<th>관리자 번호</th>
<th>사용자 번호</th>
<th>접근한 IP</th>
</tr>
</thead>
<tbody>
</tbody>
</table>
</div>
<script id="access_log_template" type="text/x-jquery-tmpl">
<tr>
<td width="">${search_ymdt}</td>
<td>${member_number}</td>
<td>${search_keyword}</td>
<td>${access_ip}</td>
</tr>
</script>실제 사용된 JSP의 내용중 일부이다. 딱 보면 알겠지만 테이블형식으로 데이터를 출력해줄 의도로 작성되었다. 여기서 script태그로 감싸진 부분이 템블릿이다. type이 text/x-jquery-tmpl인걸 보아도 알수 있다
var results = data.results;
$('#access_log_template').tmpl(results).appendTo('#access_log_table tbody');위의 템플릿과 상응하는 javascript 코드이다. data의 results를 access_log_template에 넘겨주고, 해당 템플릿은 access_log_table 테이블의 tbody 위치에다가 집어 넣겠다는 의미가 되겠다. 여기까진 좋았다. 잘 돌아갈것이라 생각했지만 예상을 가볍게 짓밟아 버렸고, 데이터가 전혀 출력되지 않았다. 여기서부터 시작이었다. 구글에서 찾은 내용으로는 분명히 저렇게 데이터를 바인딩 시키는 것이 맞았다. 하지만 안된다. 오타인가 찾아봤지만. 오타는 아니었다. 납득할수 없어서 서버만 재시작했었다. 하지만 결과는 역시 똑같았다. 이전에 이미 짜여져있던 코드에서도 템플릿을 이용하고 있었는데. 데이터 바인딩 하는게 좀 달랐다. 위 코드에서는 각 변수를 ‘${}’ 로 묶어서 바인딩 시켜줬었는데.. ‘’ 로 바인딩 시키고 있었다. 한참을 이 문제로 씨름을 하다, ‘‘를 이용해보기로 했다. 그랬는데.. 거짓말처럼 제대로 값이 출력이 되는것이 아닌가!? 매우 허무한 마음을 가지고 퇴근은 할수 있었다…
결론적으로 나는 엄청난 시간을 버렸다. 왜 그런건지 원인을 찾아보았다. 문제는 JSP EL(Expression Language)을 사용하면 jQuery tmplate와 같은 ‘${}’ 를 이용한다는 점이었다! 그렇기 때문에 JSP에서 먼저 파싱이 되서 제대로된 데이터를 출력하지 못했던 것이었다. 별것 아니라고 생각되지만.. 이걸로 고생한걸 생각하면.. :(
XMPP 는’Extensible Messaging and Presence Protocol’의 약자이다. 풀어보면 확장 가능한 메시지 및 존재(상태)를 정의한 규약쯤 될 것 같다. 쉽게 말해서 메시징 관련 프로토콜이다. 1999년 오픈소스 커뮤니티인 Jabber에 의해서 만들어진 프로토콜이라고 한다. 현재 Messsaging protocol 표준이며, 대표적으로 Google Talk, Facebook chat등에 이용되고 있다. (하지만, Facebook은 2015/04/30 이후로 deprecate, Google Talk역시 Hangout으로 넘어가면서 XMPP 지원을 하지 않는듯 하다. Slack은 XMPP gateway를 서드파티 메시징 클라이언트를 위해 지원하는 듯.)
XMPP는 XML기반으로 통신이 이루어진다. 이걸 보는 순간 ‘느린거 아닌가?’ 하는 생각이 들었다. Facebook이나 Google에서 deprecate시키는걸 보면, XML기반이라는 이유가 한몫 하지 않을까라고 생각된다. 다음은 Wikipedia에 정리되어 있는 장점 및 단점이다.
Strengths
Decentralization - 마스터 서버가 존재하지 않음.
Open Standards - 자유로이 이용가능 함. 관련 라이브러리도 풍부
History - 1999년 부터 사용되었기 때문에 여러 client, server, component, library 가 구현되어있음.
Security - XMPP 서버는 public XMPP 네트워크로부터 격리 시킬수 있고, SALS과 TLS 지원 함
Flexibility - XML 기반의 프로토콜이라 확장이 용이하며, custom application 구축이 쉬움
Weaknesses
Does not support Quality of Service (Qos) - 메시지가 잘 전송되었는지 따로 구현해야 함.
Text-based communication - text 기반의 통신이다. 순수 바이너리 솔루션에 비해 오버헤드가 크다.
In-band binary data transfer is limited - 바이너리 데이터를 base64인코딩해서 단일 XML에 첨부해야 함-> 비효율적
Does not support end-to-end encryption
특징은 대략 이 정도로 정리가 된다.
Jabber ID는 Jabber 네트워크상의 모든 유저가 가지고 있는 유일한 ID 이다. (줄여서 JID라고 불린다.) 마스터서버가 없기 때문에 Jabber ID는 마치 이메일 주소와 같은 형태를 가진다.
JID의 형태 : username@domain/resource
ex) kkw0528@nhnent.com/iPhone
resource파트를 가지고 있어서 한 유저가 각각 다른 기기로 접속할 수 있다.
두 피어간의 open-ended XML 요소를 말한다. 반드시 Root요소 이어야 하며, Stream 내부에 다수의 Stanza가 올 수 있다.
XML형식에 맞는 완전한 XML요소이다. Stream 내부에 포함되어서 전달된다. 대표적으로 presence, message, iq가 있다. message는 말그대로 메시징에 이용하는 Stanza이고, IQ는 get, set, result, error 등의 타입이 있다. get, set은 요청, result, error는 응답에 해당한다. 마지막으로 presence는 상대방이 메시지를 받을수 있는지 여부를 의미한다.
다음으로 message, iq, presence stanza에 대해 알아보자.
<message to="romeo@gmail.com" from="juliet@gmail.com" type="chat" xml:lang="en">
<body>Wherefore art thou, Romeo?</body>
</message>잘 알다시피 to는 수신자, from은 발신자를 의미한다. type은 메시지를 구별하는데 이용하며 chat 이외에도 error, groupchat, headline등의 type이 있다. xml:lang은 language에 대한 정보이다. 실제 메시지 내용은 <body></body> 안에 위치한다.
<iq from="juliet@gmail.com" type="get" id="roster_1">
<query xmlns="jabber:iq:roster"/>
</iq>juliet@gmail.com으로 부터 roster_1정보를 가져오라는 요청을 담은 IQ stanza이다. 이에 대한 응답으로 다음과 같은 roster(친구 정보)를 가져오게 된다.
<iq to="juliet@gmail.com" type="result" id="roster_1">
<query xmlns="jabber:iq:roster">
<item jid="romeo@gmail.com" name="Romeo" subscription="both">
<group>Friends</group>
</item>
<item jid="mercutio@gmail.com" name="Mercutio" subscription="from">
<group>Friends</group>
</item>
<item jid="benvolio@gmail.com" name="Benvolio" subscription="both">
<group>Friends</group>
</item>
</query>
</iq><presence xml:lang="en">
<show>dnd</show>
<status>Good night, good night! parting is such sweet sorrow, that I shall say good night till it be morrow.</status>
</presence>클라이언트는 자신의 상태를 presence stanza로 서버에 보내야 한다. show 태그 안에 상태를 표시한다. 상태의 종류는 다음과 같다.
chat - 채팅 가능한 상태.
dnd - Do not disturb.
away - 자리비움(잠시)
xa - 자리비움(오랫동안)
좀더 상세한 상태는
<presence from="romeo@gmail.com" to="juliet@gmail.com" xml:lang="en">
<show>dnd</show>
<status>Good night, good night! parting is such sweet sorrow, that I shall say good night till it be morrow.</status>
</presence>
<presence from="romeo@gmail.com" to="mercutio@gmail.com" xml:lang="en">
<show>dnd</show>
<status>Good night, good night! parting is such sweet sorrow, that I shall say good night till it be morrow.</status>
</presence>
<presence from="romeo@gmail.com" to="benvolio@gmail.com" xml:lang="en">
<show>dnd</show>
<status>Good night, good night! parting is such sweet sorrow, that I shall say good night till it be morrow.</status>
</presence>XMPP에 대해 알아보았는데, Google 및 Facebook에서 deprecate 되는것을 보니 잘은 모르지만 지고있는 표준이 아닌가 생각된다. 다음번에는 MQTT 및 message queue에 대한 내용을 알아보는 시간이 되도록 하겠다.
지난주 금요일 (2015/03/15) “장애내용을 JAM과 메일로 전파하는 프로그램 구현해주세요.” 라는 미션을 받았다. Netty 프레임워크를 이용해서… 급작스러운 미션에, 거진 처음인 Netty 프레임워크라니! 거기다가 기간도 짧았다. 어찌저찌 하루만에 동작하는 버전을 만들었다. 내심 뿌듯했었다. 그러나 오늘(2015/03/19) 장애 전파가 되지 않는다는 제보를 받았다. 매우 당황하며 원인을 찾고, 헛다리도 짚고 하다가 아미고의 도움으로(감사합니다.) 내 결과물이 원인이라는 것을 알게되었다. 내가 만든게 말썽을 일으켰으니 뭐가 문제인가 분석을 했고, 좀전에 완전히 알아냈다. 그래서 잊기전에 기록하려고 한다.
우선, JAM과 메일로 장애 전파를 하는 서버가 있다. 그리고 메신저 서버의 로그를 모니터링하다 특정 계정(장애 관련 계정)에게 메시지가 전송되면 그것을 캐치해서 장애 전파 서버로 누구에게 장애 전파 메시지를 전송해야 하는지를 알려주는 로그 모니터링 파이썬 스크립트가 있다. 슬프지만 내가 만든 서버가 문제가 있었으므로 구현한 서버에 무엇이 문제였는지를 알아보도록 하겠다.
어찌된 이유인지(지금은 알고있지만..) 리퀘스트를 보내도 리퀘스트 내용이 아닌 어제 보냈던 그림과같이 메시지 및 메일이 도착했다.
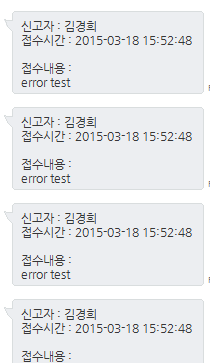
메일 역시 같은 내용으로 전송이 되고있었다.
가장 큰 원인은 내 미숙함이었다.
자세하게 얘기하자면, 리퀘스트가 들어올때마다 HTTP content를 저장하는 StringBuilder 객체가 초기화 되지 않은것이 이유였다. 그래서 리퀘스트가 들어올때마다 HTTP content의 내용들이 차곡차곡 쌓이고 있는 상황이었던 것이다. 초기화 안했던것은 아니었다. 다만 호출이 되지 않았을뿐… HTTP content의 내용이 json이라서 json string을 읽어올때 맨 앞의 완전한 블록 하나만 파싱했기 때문에 계속 맨앞의 메시지가 전송되고 있었던것이라 생각된다.소스코드를 보면서 좀더 자세하게 들여다보자.
@Override protected void channelRead0(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof HttpRequest) {
HttpRequest request = this.request = (HttpRequest) msg;
if (HttpHeaders.is100ContinueExpected(request)) {
send100Continue(ctx);
}
buf.setLength(0); //문제의 부분
}
if (msg instanceof HttpContent) {
HttpContent httpContent = (HttpContent) msg;
ByteBuf content = httpContent.content();
if (content.isReadable()) {
buf.append(content.toString(CharsetUtil.UTF_8));
}
if (msg instanceof LastHttpContent) {
GLoggerFactory.getInstance().setLoggerClass(TtsNotificationLogger.class);
GMCoreServer core = new GMCoreServer(host, port, (short) 1, isSecure, new ConnectionLostListener() {
@Override
public void onConnectionLost() {
System.out.println("connection lost");
}
});
String jsonRequest = buf.toString();
NotiContent notiContent = getRequestContents(jsonRequest);
NotificationController noti = new NotificationController();
noti.sendNotification(core, notiContent);
//buf.setLength(0); //바꾼 위치
}
}
}파이썬 스크립트로부터 HTTP 리퀘스트를 받으면 해당 메소드로 진입하게 된다. 문제의 부분을 보자. 분명히 멤버 변수인 buf (StringBuilder)를 초기화 해주고 있다. 그러나 실제 동작은 예전데이터가 망령처럼 나타나서 장애 메시지 및 메일로 전송되고 있었다! Netty 프레임워크의 example code 에서는 분명 저 위치였는데 동작했었다!! buf.setLength(0) 의 위치를 바꿔보라는 아미고의 말에 수긍하기 어려웠지만 옮겼다. 그랬더니 되는것이 아닌가! 눈으로는 목격했지만 머리로는 이해가 되지 않았다. 그래서 좀더 살펴보기로 했다.
좀더 깊숙히 들어가서 상황 설명을 하자면, 나는 URL 라우팅을 하고싶었다. 해당 서버 IP로 아무렇게나 리퀘스트를 날려도 수행되게 할수는 없으니까… 방법을 잘 몰랐기에 구글에 문의했다. 고맙게도 누군가 만들어 놓은 라이브러리가 있었다. 이름은 netty-router. 내가 직접 짜는거보다 훨씬 깔끔하게 이용할 수 있을것 같았다. 그래서 이용했는데 이게 해당 버그의 원인이었다!
public class TtsNotificationInitializer extends ChannelInitializer<SocketChannel> {
private static final Router router = new Router()
.POST("/sendnoti", new TtsNotificationServerHandler()); //after
private static final Handler handler = new Handler(router); //after
private final SslContext sslCtx;
public TtsNotificationInitializer(SslContext sslCtx) {
this.sslCtx = sslCtx;
}
@Override
public void initChannel(SocketChannel ch) {
ChannelPipeline p = ch.pipeline();
if (sslCtx != null) {
p.addLast(sslCtx.newHandler(ch.alloc()));
}
p.addLast(new HttpRequestDecoder());
// Uncomment the following line if you don't want to handle HttpChunks.
//p.addLast(new HttpObjectAggregator(1048576));
p.addLast(new HttpResponseEncoder());
// Remove the following line if you don't want automatic content compression.
//p.addLast(new HttpContentCompressor());
p.addLast(handler.name(), handler); //after
//p.addLast(new TtsNotificationServerHandler()); //before
}
}서버를 초기화 해주는 클래스이다. 이전 소스코드는 before, netty-router를 이용하면서 고친 소스코드는 after로 표기했다. Router와 Handler를 위와 같이 생성해서 ChannelPipeline 에 추가해주면 간단하게 완성된다. 이렇게 함으로써 서버는 sendnoti로 POST요청 들어올 때만 서비스를 해주게 된다. 여기까진 좋았다. 위에 보았던 소스코드 일부분을 다시보자.
@Override protected void channelRead0(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof HttpRequest) {
HttpRequest request = this.request = (HttpRequest) msg;
if (HttpHeaders.is100ContinueExpected(request)) {
send100Continue(ctx);
}
buf.setLength(0); //문제의 부분
}다시 문제의 부분이다. buf.setLength(0) 가 수행되지 않은 이유를 설명하겠다. netty-router를 이용하기 전에는, 요청이 들어오면 msg가 HttpRequest의 구현체(DefaultHttpRequest) 로 넘어온다. 때문에 (msg instanceof HttpRequest) 가 참이 되고, if 블록 안의 코드가 수행된다. 하지만, netty-router를 이용하면 msg가 Routed 라는 객체 타입으로 넘어오게된다. 때문에 (msg instanceof HttpRequest) 가 거짓이 된다. 결과적으로 if 블록은 수행되지 않게되고, 이로인해 잘못된 동작을 하고 있었다.
최대한 편하게 작성하려했지만 그때는 좀 기분이 그랬다. 장애 알림 서버가 장애라니! 이번에 깨달은건, “역시 제대로 알고 써야겠구나.” 와 “테스트 할 때 제대로 해야되는구나.” 두가지이다. 테스트 할때 잘 잡아내기만 했어도 이렇지는 않았을 것이다.
각 서버 노드들이 분산된 환경에서는 서버 하나로 이루어진 환경에서 보다 고려해야할 것이 많다. 각 노드들 간의 네트워크는 물론이고, 각 노드들의 동작여부, 각 노드들의 부하 여부 등.. 이 밖에도 많이 존재할 것이다. Consistent hashing은 이런 분산 환경에서 각 노드들로 리퀘스트가 들어올 경우 어떤 서버에 할당을 하는가에 대한 방법 중 하나이다. Consistent hashing은 부하 분산에 효과적이며 서버 failure 시에 효과적인 대응을 가능하게 한다. Consistent hashing은 Karger에 의해 논문[1,2] 으로 발표 되었다. Karger는 Consistent hanshing을 이용하면 웹 서버의 대수가 변화하는 환경에서 효과적인 요청 처리를 할 수 있다고 주장하고 있다. Consistent hashing은 현재 Redis, memcached, cassandra 등에서 많이 이용되고 있는 기술이다.
Consistent hashing은 해싱 알고리즘을 이용한다. 기본적으로 Consistent hashing의 구조는 Hash ring을 생각하면 이해하기 쉽다. 각 노드들은 각각 해시 범위를 가지고 있다. 사용하는 해시 알고리즘의 범위가 0~99의 범위를 가진다면, 각 노드들은 0~99범위안에서 해시 범위를 나눠 가지게된다. 총 노드가 4개라면 0~24, 25~49, 50~74, 75~99의 범위를 나눠 갖게된다. 만약 데이터가 들어온다면 데이터의 해시 값이 포함되는 범위를 가진 노드에 저장되게 된다.
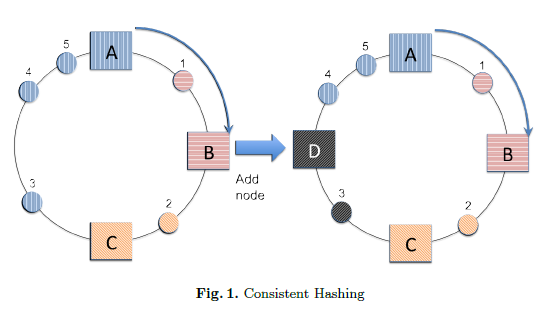
Fig.1 에서 볼수 있듯이 consistent hashing은 Hash ring구조로 되어있다. Hash ring 상의 사각형은 데이터가 저장될 서버 노드를 나타내고, 원은 데이터를 의미한다. Fig.1 의 왼쪽 그림에서, 1번 데이터는 B노드, 2 번 데이터는 C노드, 3, 4, 5 데이터는 A 노드에 저장되어 있다. 각 노드는 각각 해시 범위를 가지고 있어서, 각 데이터는 데이터의 해시값을 포함하는 서버 노드에 저장되게 된다. 만약 D 노드가 추가 된다면, D 노드는 해시범위를 나눠 가지고 해당 범위에 속하는 3 번 데이터가 D 노드에 속하게 된다.
일반적인 데이터의 부하 분산방법으로는 데이터의 해시값 % server 의 대 수 로 저장될 서버를 결정하는 것이다. 그러나 이 경우 서버가 추가되거나 장애등으로 제외된다면 저장된 모든 데이터를 다시 계산해서 이동시켜야 하는 상황이 발생한다. 이런 연산은 전체 데이터를 대상으로 연산되므로 시스템의 큰 부하를 가져오게 된다.
그렇다면, Consistent hashing 은 어떤가 살펴보도록 하자.
첫번째로, 서버 노드가 삭제 되었을 경우이다. Fig.1 의 오른쪽 Hash ring에서 노드 B 가 장애등의 이유로 제외된다고 가정하자. 데이터 1 은 유실이 되고, 노드 B가 담당하고 있던 해시 범위는 노드 C 가 담당하게 된다. 그 외의 데이터 migration은 발생하지 않는다. 만약, 데이터의 해시값 % server 의 대 수로 저장될 서버를 결정한다면 노드가 제외됬을 경우 전체 데이터에 대한 연산이 발생하게 될 것이다.
두번째로, 서버 노드가 추가 되었을 경우이다. 이 경우에는 앞에서 설명했듯이 Fig.1 의 왼쪽그림에서 노드 D 가 추가되는 상황이랑 같다. 데이터 3 만 노드 D로 할당될 뿐 다른 노드들에 저장된 데이터들은 이동할 필요가 없다.
Consistent hashing의 단점이라고 한다면, 부하 분산을 해시 알고리즘에 의존하게 된다는 점이다. 사용하는 해시 알고리즘의 Uniform distribution 이 좋지 않다면 부하 분산이 잘 되지 않을 것이다. 이를 해결하기 위해 실제 서버 노드 외에 임의 가상노드를 이용하여 문제를 해결 하고 있다. 실제로 Cassandra에서는 virtual node를 이용하고 있다.